【简介】
在行为识别任务中,受制于数据量以及算法的制约,基于RGB图像的行为识别模型常常会受到视角的变化以及复杂背景的干扰,从而导致泛化性能不足,很难应用到实际生活中。而基于骨骼点数据的行为识别可以较好地解决这个问题。
在骨骼点数据中,人体是由若干预先定义好的关键关节点在相机坐标系中的坐标来表示的。它可以很方便地通过深度摄像头(例如Kinect)以及各种姿态估计算法(例如OpenPose)获得。图 1是Kinect深度摄像机所定义的人体的关键关节点。它将人体定义为25个关键关节点的三维坐标。由于行为往往是以视频的形式存在的,所以一个长度为T帧的行为可以用Tx25x3的张量来表示。
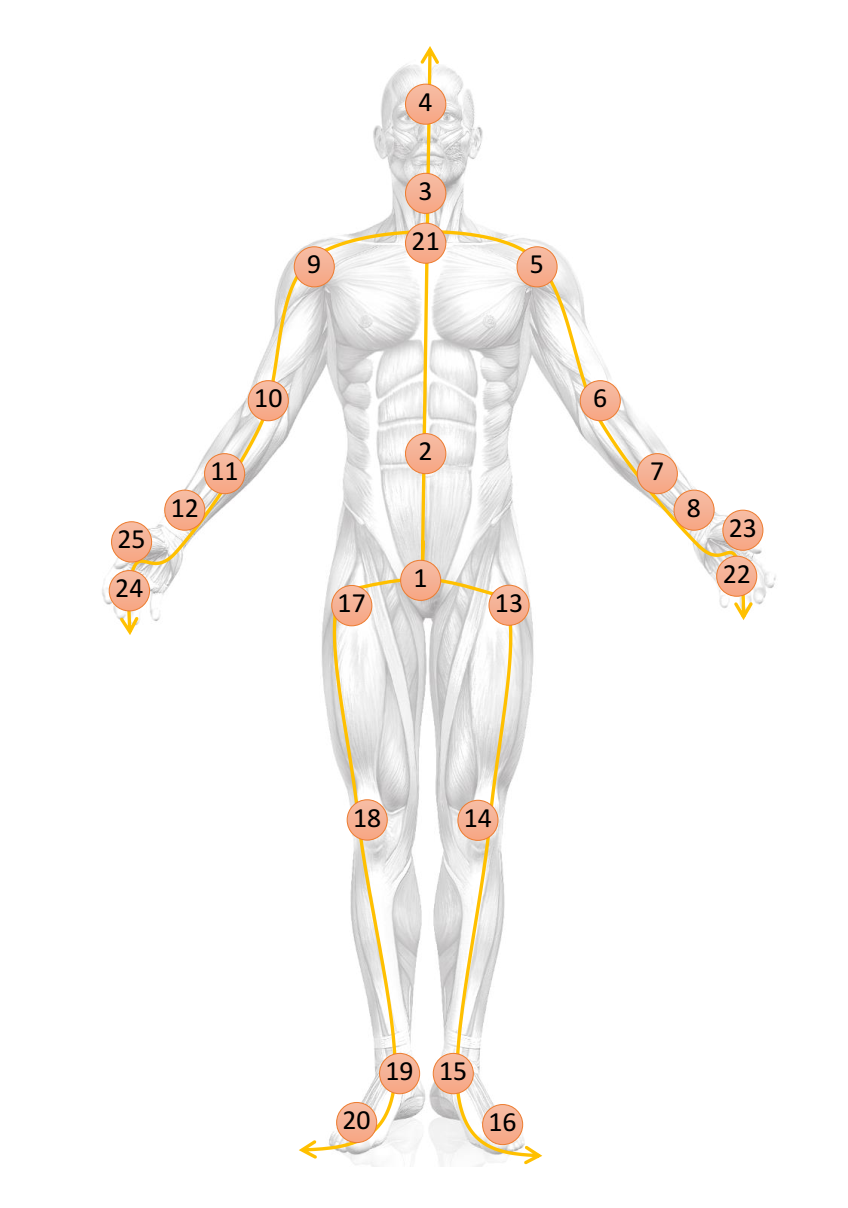
图1 Kinect相机定义的关键关节点
【相关工作】
传统的基于骨骼点行为识别的深度学习方法主要分为基于RNN的和基于CNN的:基于RNN的方法将数据表示为三维向量的序列,然后利用LSTM等序列模型来建模;基于CNN的方法会人工设计一些规则把骨骼点数据转换成一张伪图像,然后利用图片分类中的模型进行对其识别。
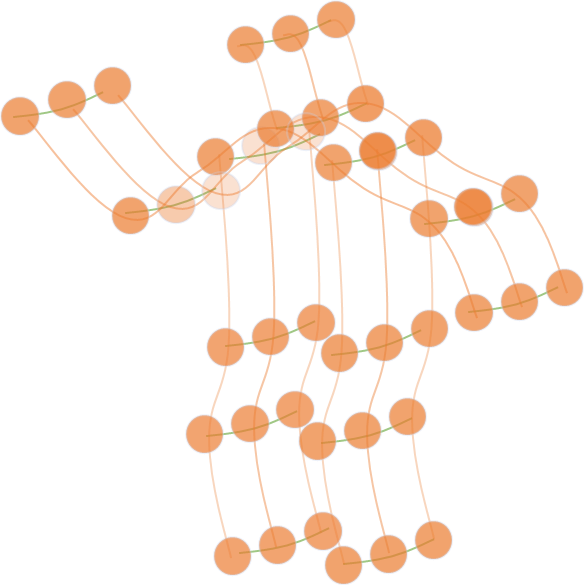
但其实骨骼点数据更自然地是一种图的形式。在AAAI2019的工作ST-GCN[1]中,作者将每个关节点定义为图的节点,关节点之间的物理连接定义为图的边,并且在相邻帧的同一个节点间加上时间维度的边,这样一个行为便可以由一张时空图(如图 2)来表示。
图2 行为时空图
那么如何通过这张时空图来识别行为呢?作者提出采用图卷积的方式。和普通卷积操作不同,在图上做卷积时,每一个节点的邻节点数是不固定的,但是卷积操作的参数是固定的,所以需要定义一个映射函数来将固定数量的参数和不定数量的临节点数对应起来。这里作者定义卷积核大小为三,三个参数分别对应于远离人体中心(图3 的X点)的点(图3的蓝色点),靠近人体中心的点(图3的绿色点)和卷积点本身(图3的红色点)。
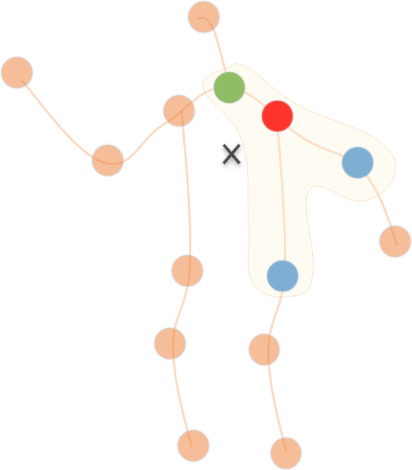
图3 图卷积
这样卷积操作就可以表示为:

其中f是输入输出的特征张量,w是卷积参数,v是图中节点,l代表上述的节点与参数间的映射函数,Z是归一化函数。在具体实现时,映射函数可以通过图的邻接矩阵来实现,表示为:
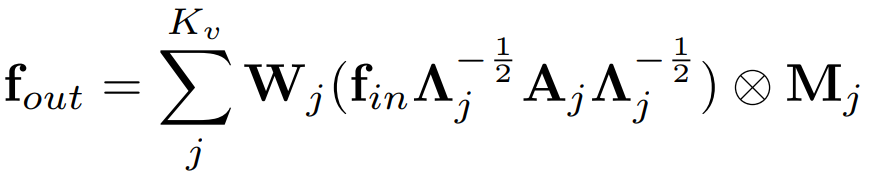
其中A代表图的邻接矩阵,K是卷积核大小。通过与邻接矩阵相乘,我们可以从特征张量中“筛选”出所需要的节点并与对应的参数相乘。
【相关工作存在的问题】
我们经过实验发现,ST-GCN的方法有两个缺陷:
1. ST-GCN中的图的拓扑结构是根据人体的物理结构定义的,这样定义的图并不一定适用于行为分类的任务。例如人体的两只手之前是没有物理连接的,在图中手之间的距离也会比较远。但是对于鼓掌这个行为,建模两只手之间的关系明显是更为重要的。另外,神经网络是多层结构,在不同的层中所包含的信息也是不同的。往往高层的网络会包含更偏向语义的信息,那么对所有的层使用相同拓扑结构的图也是不合理的。
2.
在我们观察一个人的时候,相比于每个关节点的位置,人体各个肢体的方向,长度其实对于行为识别是更明显的特征。而在之前的工作中却都忽视了这一点。
【我们的方法】
针对以上两个问题,实验室图像与视频分析团队博士生史磊、张一帆副研究员等提出了一种双流自适应的图卷积神经网络来建模人体骨架并进行行为识别。论文已被国际会议CVPR2019接收。
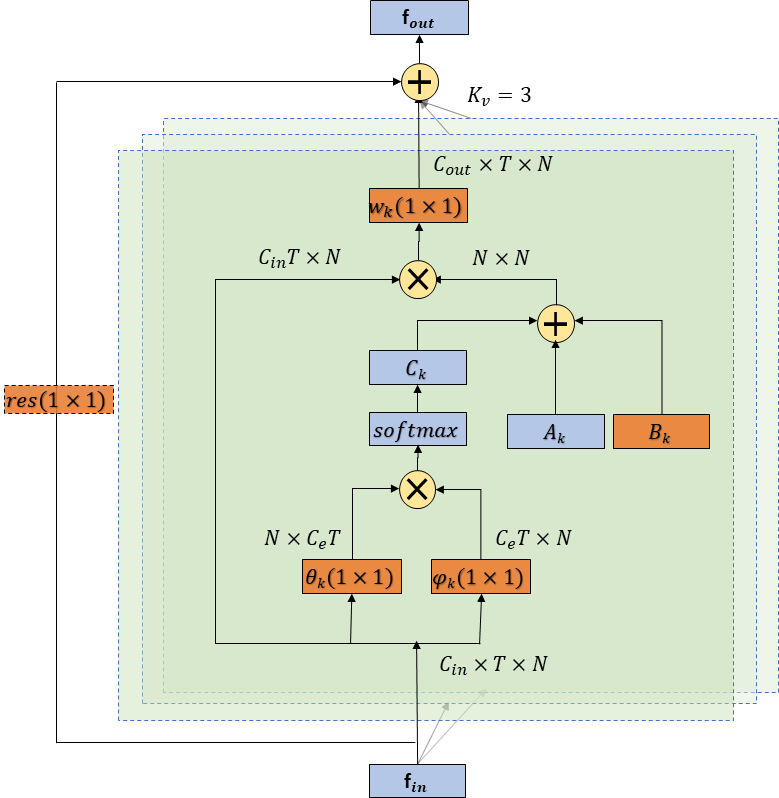
图4 自适应图卷积层
针对第一个问题,我们设计了一个自适应的图卷积层(图 4)。这里我们定义了三种图,其中A代表了根据人体物理结构定义的图,它对于所有的卷积层以及所有的样本都是相同的。B是根据数据库统计出来的适应于行为识别任务的图,它会作为网络的参数在训练过程中根据分类损失不断更新,它对于每一个卷积层都是不同的,但是对于不同样本是相同的。C是样本自适应的图,这里我们借鉴了双线性注意力机制的形式来设计[2], [3]。我们会首先将输入通过φ和θ函数降维映射到一个低维空间,然后通过相乘获得每两个点之前的特征相似性,然后将这个相似性矩阵通过softmax归一化作为最终的邻接矩阵。这个过程可以表示为:
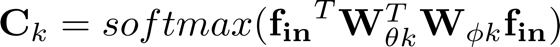
最终的自适应图卷积层可以表示为:
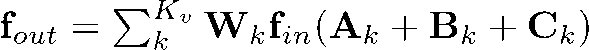
针对第二个问题,我们在实验中单独提取了人体骨骼的信息,表示为关节点之间的向量。借鉴了行为识别中常用的双流框架[4],我们将骨骼的信息使用另一个自适应图卷积神经网络来建模,然后将骨骼流(Bone)于关节点流(Joint)的softmax层分数融合来得到最终的分类结果。
【实验结果】
为了于ST-GCN比较,我们在NTU-RGB+D和Kinetics-Skeleton两个数据库上进行了实验。由于骨骼点数据往往包含很多噪声,我们首先对数据进行了一些去噪操作,将基准值提升到了92.7。接着我们在NTU-RGB+D数据库上我们进行了消融实验,结果如下:
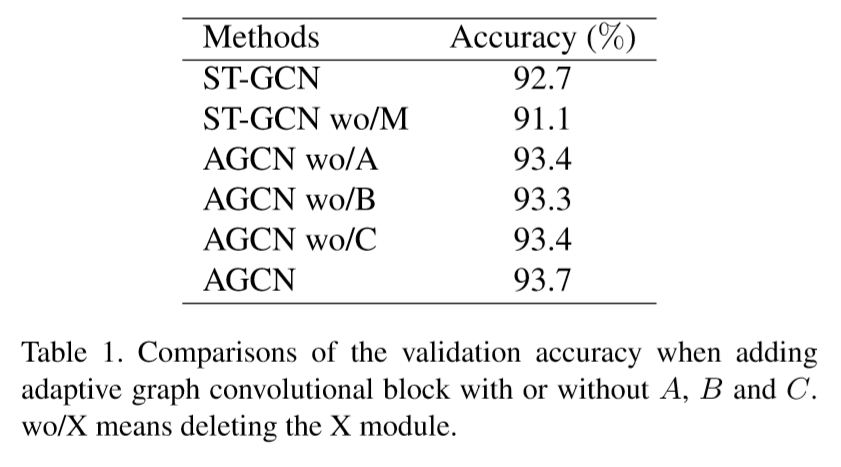
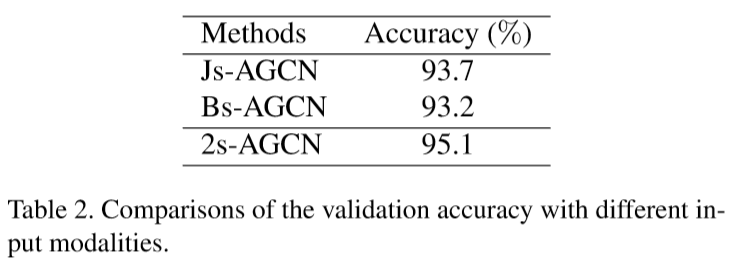
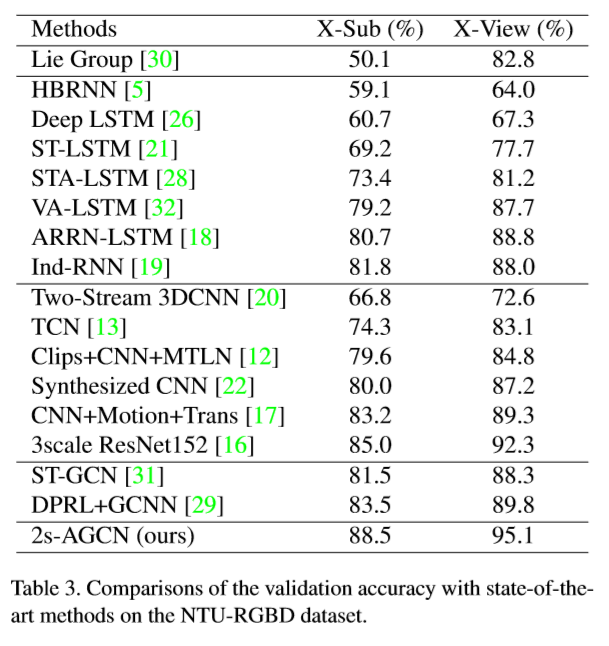
从中可以看出我们所提出的自适应图卷积层和双流法都有明显的效果。最终在NTU-RGB+D和Kinetics-Skeleton上我们都取得目前最好的结果,并且较之前的方法都有很大的提升(~7%)。

论文信息:
Lei Shi, Yifan Zhang, Jian Cheng and Hanqing Lu, "Two-Stream Adaptive Graph Convolutional Networks for Skeleton-Based Action Recognition," in Proceedings of IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Long beach, USA, 2019.
Reference
[1] S. Yan, Y. Xiong and D. Lin, Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition, AAAI, 2018.
[2] A. Vaswani et.al., Attention is All you Need, Advances in Neural Information Processing Systems 30, 2017, 6000–6010.
[3] X. Wang, R. Girshick, A. Gupta and K. He, Non-Local Neural Networks, The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[4] K. Simonyan and A. Zisserman, Two-stream convolutional networks for action recognition in videos, Advances in neural information processing systems, 2014, 568–576.
|