Introduction
The “CASIA-Tencent Chinese Traffic Sign Understanding Dataset” (CTSU Dataset) was built by the National Laboratory of Pattern Recognition (NLPR), Institute of Automation of Chinese Academy of Sciences (CASIA), and T Lab, Tencent Map, Tencent Technology (Beijing) Co., Ltd. The images in our dataset are from car camera videos of cities in China. The area covered includes not only developed areas such as urban streets, urban expressways, and highways, but also some underdeveloped areas such as rural roads. Our CTSU Dataset contains 5000 traffic signs, 16463 descriptions, 31536 relationship instances, 43722 components, including 18280 texts, which provides abundant annotations for traffic sign understanding. All images are divided into a training set of 4000 images and a test set of 1000 images with the same category distribution.
CASIA-Tencent CTSU.zip (232.6MB)
Annotations
1. Sign Categories: All traffic signs are manually classified into 13 categories. The names and numbers of these categories are shown in Table.1.
Table.1
|
id |
category |
number |
|
1 |
Guidance information |
1100 |
|
2 |
Lane information |
900 |
|
3 |
Direction information |
1000 |
|
4 |
Service area |
420 |
|
5 |
One-way lane |
50 |
|
6 |
Turn around |
50 |
|
7 |
Underground tunnel |
50 |
|
8 |
Bicycle lane |
250 |
|
9 |
Bus lane |
600 |
|
10 |
Yield to peds |
100 |
|
11 |
Emergency lane |
200 |
|
12 |
Speed measurement |
100 |
|
13 |
Roadside sign |
180 |
Our dataset is unbalanced. Users can use some image enhancement methods, such as color jittering, slight angle rotation, and image distortion.
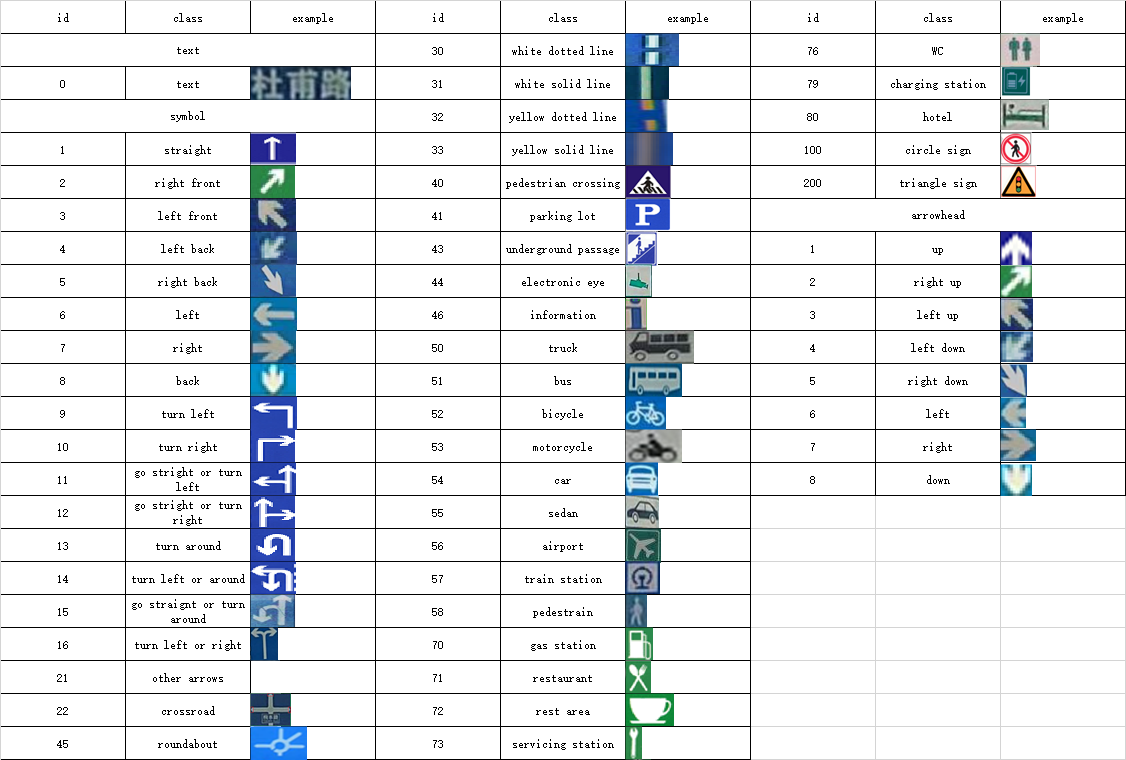
2. Components: Components in traffic signs include texts and symbols. Here we divide all the components into three groups: texts, symbols, and arrowheads. All the components and their class ids can be found in Table.2.
Table.2
3. Relations: Relations defined in CTSU Dataset include two types: association relation and pointing relation.
4. Sematic Descriptions: Semantic descriptions are in form of <key: value>, in which the items in value all belong to a specific place name or road name, and they are out of order.
5. Information Matching Metric: Our IM
metric can be available in the following script eval_im.zip (4KB).
Dataset Format
Annotation files are organized in JSON format. The name of the picture and the corresponding annotation file are the same. The format of the annotation file is as follows:

Performances of our methods
The performances of our methods in paper [1] and [2] are shown in Table 1. Notably, due to the entity category annotations newly included in semantic descriptions, the results of information matching differ from those in paper [1].
Table.3

[1] Guo Y, Feng W, Yin F, et al. Learning to understand traffic signs[C]//Proceedings of the ACM International Conference on Multimedia (ACM MM), 2021: 2076-2084.
[2] Guo Y, Feng W, Yin F, et al. SignParser: An End-to-End Traffic Sign Understanding Framework [J]//International Journal of Computer Vision (IJCV), 2023: 1-17.
Condition of Use
Reference
The CTSU Dataset was first used in the research work refered to as
Yunfei Guo, Wei Feng, Fei Yin, Tao Xue, Shuqi Mei and Cheng-Lin Liu. Learning to Understand Traffic Signs[C]//Proceedings of the ACM International Conference on Multimedia (ACM MM), 2021: 2076-2084.
Contact
Cheng-Lin Liu (liucl@nlpr.ia.ac.cn), Fei Yin (fyin@nlpr.ia.ac.cn)
National Laboratory of Pattern Recognition (NLPR)
Institute of Automation of Chinese Academy of Sciences
95 Zhongguancun East Road, Beijing 100190, P.R. China
24th International Conference on Pattern Recognition
15th International Conference on Frontiers in Handwriting Recognition
10th IAPR-TC15 Workshop on Graph-based Representations in Pattern Recognition
Haidian | Beijing | China
Phone : (+86-10)8254-4797
Fax : (+86-10) 8254-4594
Email:liucl@nlpr.ia.ac.cn
Website:www.nlpr.ia.ac.cn/pal/