A Performance Evaluation of Local Features for Image-Based 3D Reconstruction
Bin Fan1,2, Qingqun Kong2,3, Xinchao Wang4, Zhiheng Wang5, Shiming Xiang1,2, Chunhong Pan1,2, and Pascal Fua6
1National Laboratory of Pattern Recognition, China
2Institute of Automation, Chinese Academy of Sciences, China
3University of Chinese Academy of Sciences, China
4Steven Institute of Technology, USA
5Henan Polytechnic University, China
6CVLab, EPFL, Switzerland
Brief Introduction
This paper performs a comprehensive and comparative evaluation of the state of the art local features for the task of image based 3D reconstruction. The evaluated local features cover the recently developed ones by using powerful machine learning techniques and the elaborately designed handcrafted features. To obtain a comprehensive evaluation, we choose to include both float type features and binary ones. Meanwhile, two kinds of datasets have been used in this evaluation. One is a dataset of many different scene types with groundtruth 3D points, containing images of different scenes captured at fixed positions, for quantitative performance evaluation of different local features in the controlled image capturing situation. The other dataset contains Internet scale image sets of several landmarks with a lot of unrelated images, which is used for qualitative performance evaluation of different local features in the free image collection situation. Our experimental results show that binary features are competent to reconstruct scenes from controlled image sequences with only a fraction of processing time compared to use float type features. However, for the case of large scale image set with many distracting images, float type features show a clear advantage over binary ones. Currently, the most traditional SIFT is very stable with regard to scene types in this specific task and produces very competitive reconstruction results among all the evaluated local features. Meanwhile, although the learned binary features are not as competitive as the handcrafted ones, learning float type features with CNN is promising but still requires much effort in the future.
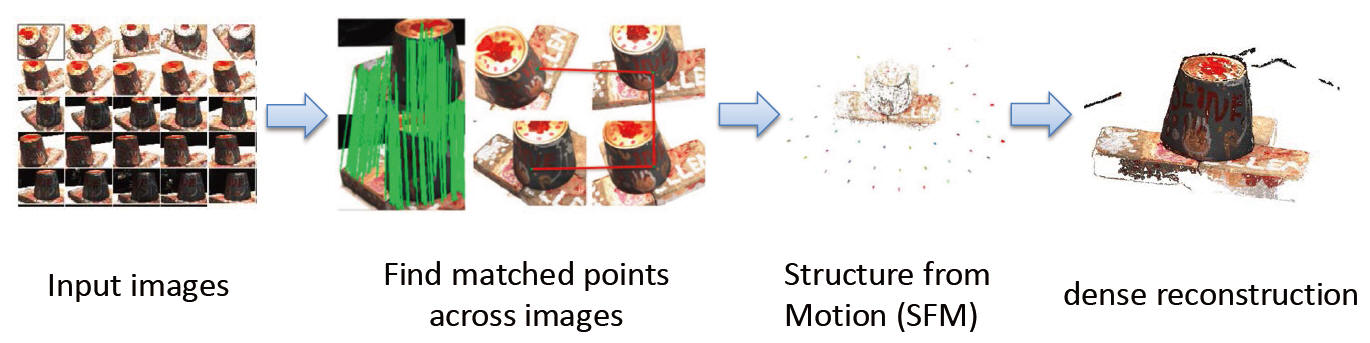
Under the above pipeline for image based 3D reconstruction, we focus on the second step: studying how feature matching performance of different local features will affect the final reconstruction results.
Our experimental results reveal that for the controlled case where no distracting images exist, using binary features is good enough to produce the state of the art 3D reconstruction results with only a fraction of time of using float type features. However, for the large scale freely collected image set with many distractors, using binary features can not guarantee the good performance. The float type descriptors are the most competitive ones in this case even though they need more time to establish point correspondences. Among the evaluated float type descriptors, using recently learned descriptors, such as VGGDesc and L2Net, can lead to better results than using handcrafted ones (SIFT, LIOP). However, the pioneering CNN-based descriptor learning method (DeepDesc) is not as competitive as these two learned descriptors. Meanwhile, the most traditional SIFT also produces very good results among all the evaluated features, which explains the fact that SIFT is still the primary choice for this task. This also implies that it still requires a lot of efforts to improve the general matching performance of local features. The good results of the learned descriptors further encourage the potential of learning descriptors, but it has to be significantly better and much more robust than the existing SIFT so as to replace it in this task. What is more, how to learn the whole stuff of feature detection and description together still requires lots of works to do, as shown by the results of LIFT which are even inferior to the baseline in some cases. Finally, as binary features are rather competitive in controlled image capturing situation while preserving computational and memory efficiency, it is necessary to develop more powerful binary features with high discriminative ability so as to make them suitable for more general case of image based 3D reconstruction.
Paper
Bin Fan, et al. A Performance Evaluation of Local Features for Image-Based 3D Reconstruction, IEEE Transaction on Image Processing, 2019.
@article{Fan_TIP2019,
title={A
Performance Evaluation of Local Features for Image-Based 3D
Reconstruction},
author={Bin Fan and Qingqun Kong and Xinchao Wang and
Zhiheng Wang and Shiming Xiang and Chunhong Pan and Pascal Fua},
journal={IEEE Transactions on Image Processing},
year={2019}
}
Software
The source codes/models of the evaluated features can be downloaded from their authors' websites (please see the references below), or you can use our integrated one here [code].
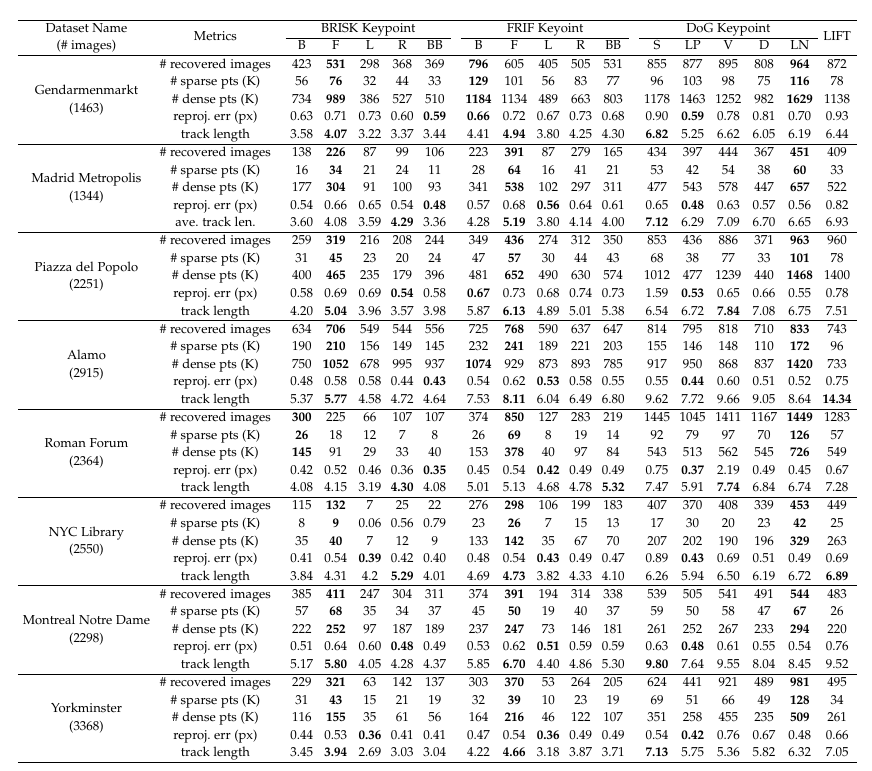
Results on the large scale SFM dataset[1]
Evaluated features:
B: BRISK[2], F: FRIF[3], L: LDB[4], R: RFDR[5], BB: BinBoost256[6], S: SIFT[7], LP: LIOP[8], V: VGGDesc[9], D: DeepDesc[10], LN: L2Net[11], LIFT[12]
Results on the DTU-MVS dataset[13]

References
[1] K. Wilson and N. Snavely. "Robust global translation with 1dsfm". ECCV 2014. [dataset link]
[2] BRISK: S. Leutenegger, M. Chli, and R. Siegwart. "BRISK: Binary robust invariant scalable keypoints". ICCV 2011. [code]
[3] FRIF: Z.Wang, B. Fan, and F. Wu. "FRIF: Fast robust invariant feature". BMVC 2013. [code]
[4] LDB: X. Yang and T. Cheng. "Local difference binary for ultra-fast and distinctive feature description". IEEE TPAMI 2014. [code]
[5] RFD: B. Fan, Q. Kong, T. Trzcinski, Z. Wang, C. Pan, and P. Fua. "Receptive fields selection for binary feature description". IEEE TIP 2014. [code]
[6] BinBoost: T. Trzcinski, M. Christoudias, and V. Lepetit. "Learning image descriptors with boosting". IEEE TPAMI 2015. [code]
[7] SIFT: D. Lowe. "Distinctive image features from scale-invariant keypoints". IJCV 2004. [vlfeat's implementation]
[8] LIOP: Z. Wang, B. Fan, and F. Wu. "Local intensity order pattern for feature description". ICCV 2011. [code]
[9] VGGDesc: K. Simonyan, A. Vedaldi, and A. Zisserman. "Learning local feature descriptors using convex optimisation". IEEE TPAMI 2014. [code]
[10] DeepDesc: E. Simo-Serra, E. Trulls, L. Ferraz, I. Kokkinos, P. Fua, and F. Moreno-Noguer. "Discriminative learning of deep convolutional feature point descriptors". ICCV 2015. [code]
[11] L2Net: Y. Tian, B. Fan, and F. Wu. "L2Net: deep learning of discriminative patch descriptor in euclidean space". CVPR 2017. [code]
[12] LIFT: K. M. Yi, E. Trulls, V. Lepetit, and P. Fua. "LIFT: learned invariant feature transform". ECCV 2016. [code]
[13] R. Jensen, A. Dahl, G. Vogiatzis, E. Tola, and H. Aanæs. "Large scale multi-view stereopsis evaluation". CVPR 2014. [dataset link]
Bin Fan, bfan@nlpr.ia.ac.cn