EgoGesture is a multi-modal large scale dataset for egocentric hand gesture recognition. This dataset provides the test-bed not only for gesture classification in segmented data but also for gesture detection in continuous data.
The dataset contains 2,081 RGB-D videos, 24,161 gesture samples and 2,953,224 frames from 50 distinct subjects. We design 83 classes of static or dynamic gestures focused on interaction with wearable devices as shown in Figure 1.

Figure 1. The eighty-three classes of hand gestures designed in EgoGesture dataset.
The videos are collected from 6 diverse indoor and outdoor scenes. We also consider the scenario when people perform gestures while walking. The 6 scenes we designed consist of 4 indoor scenes:

Figure 2. Some examples of the 6 scenes.
Figure 3 demonstrate the sample distribution on each subject in the 6 scenes. In the figure, the horizontal axis and the vertical axis indicate the subject ID and the number of the samples, respectively. We use different colors to represent different scenes. The numeral on each color bar represents the number of gesture samples in the corresponding scene recorded with the subject corresponding to the ID in the horizontal axis. There are 3 subjects (i.e. Subject 3, Subject 7 and Subject 23) who did not record videos in all the 6 scenarios. The total number of gesture samples of each subject is also listed above the stacked bars.
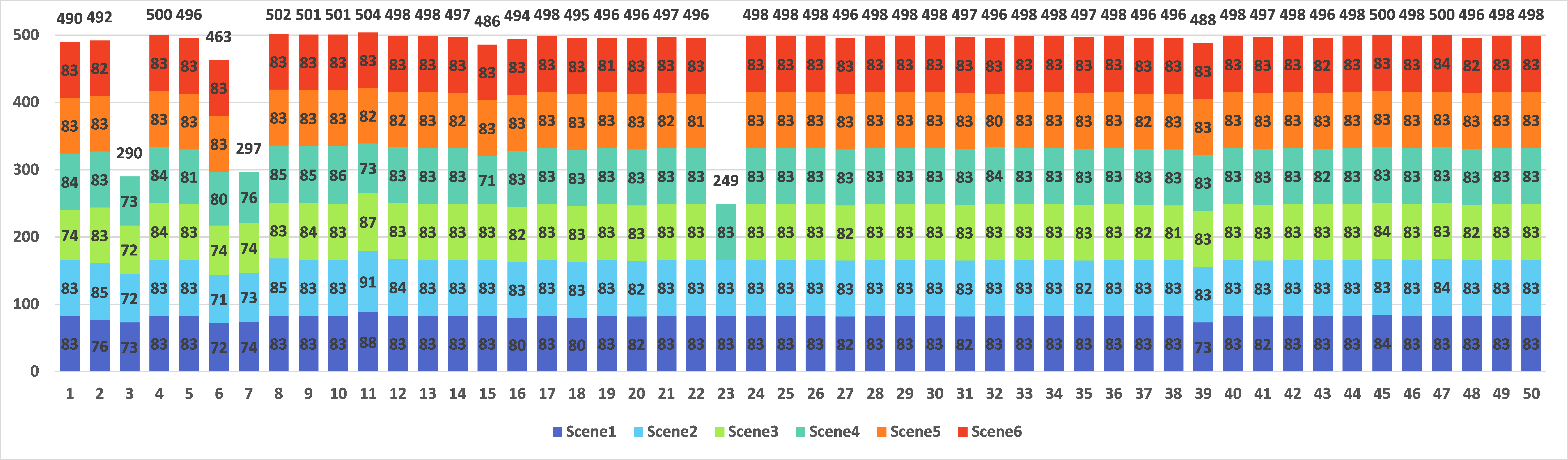
Figure 3. The distribution of the gesture samples on each subject in EgoGesture dataset. The horizontal axis and the vertical axis indicate the subject ID and the sample numbers respectively.
We select Intel RealSense SR300 as our egocentric camera due to its small size and integrating both RGB and depth modules. The two-modality videos are recorded in a resolution of 640ⅹ480 pixel with 30 fps. The subjects wearing the RealSense camera with a strap belt on their heads are asked to continuously perform 9-14 gestures as a session and recorded as a video. Since the order of the gestures performed is randomly generated, the videos can be used to evaluate gesture detection in continuous stream. Besides the annotation of class label, the start and end frame index of each gesture sample are also manually labeled, which provides the test-bed for segmented gesture classification.
In our experiments, we randomly split the data by subject into training (SubjectID: 3, 4, 5, 6, 8, 10, 15, 16, 17, 20, 21, 22, 23, 25, 26, 27, 30, 32, 36, 38, 39, 40, 42, 43, 44, 45, 46, 48, 49, 50), validation (SubjectID: 1, 7, 12, 13, 24, 29, 33, 34, 35, 37) and testing (SubjectID: 2, 9, 11, 14, 18, 19, 28, 31, 41, 47) sets with the ratio of 3:1:1, resulting in 1,239 training, 411 validation and 431 testing videos. The numbers of gesture samples in training, validation and testing splits are 14416, 4768 and 4977 respectively.
We provide the original RGB-D videos (~46G), a file of images resized to 320ⅹ240 pixel (~32G) and the annotations for downloading. There are three columns of text in an annotation file respectively representing the class label, the start and the end frame index of each gesture sample in a video.
videos/Subject01/Scene1/Color/rgb1.avi
…
videos/Subject01/Scene1/Depth/depth1.avi
…
images_320-240/Subject01/Scene1/Color/rgb1/000001.jpg …
…
images_320-240/Subject01/Scene1/Depth/depth1/000001.jpg …
…
labels-revised1/subject01/Scene1/Group1.csv
…
To obtain the database, please follow the steps below:
The database is released for research and educational purposes. We hold no liability for any undesirable consequences of using the database. All rights of the EgoGesture Database are reserved.
If you use our dataset, please kindly cite the following papers: